AI 视频生成已经很强大了,但“生成失败”仍然是最让人头疼的问题之一。产品可能会突然变形,参考图可能会被无视,详细提示词也可能只被模型抓住一个大概意思,最后做出来的视频和你真正想要的镜头方案差很远。
所以我想从更实用的角度测试一下 HappyHorse 1.0:它能不能减少那些最容易浪费时间、积分和创作精力的常见错误?
这次实测里,我用 HappyHorse 1.0 做了三种不同测试:先用一张 DJI Pocket 3 产品图看产品一致性,再用五张参考图测试它对多角度产品的理解能力,最后再用一个纯文本的咖啡馆提示词,看它对多镜头机位指令的遵循程度。
测试 1:Image-to-Video:产品一致性
为了测试 HappyHorse1.0 能否把一张 DJI Pocket 3 产品图变成一支适合产品展示、观感又足够酷的 5 秒宣传短片,我做了一个快速实验。
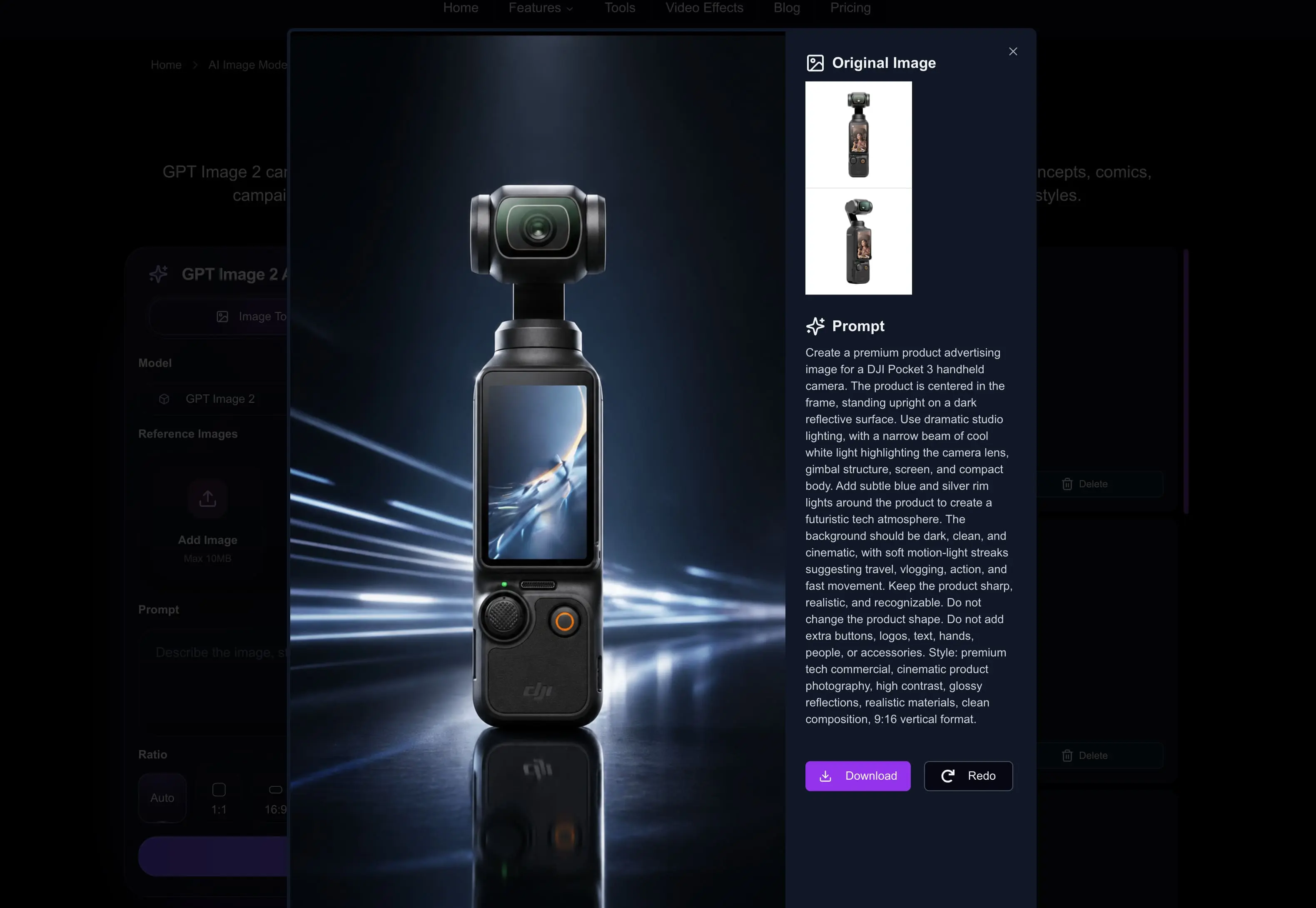
为了提高稳定性,我并没有直接把产品图丢进视频模型里听天由命。相反,我先用 GPT Image 2 生成了一张更完整的产品广告图,再把这张图作为视频首帧,最后再交给 HappyHorse1.0 生成一支 5 秒视频。
我先在浏览器里打开 Lanta AI 的 AI Video Generator 页面,然后在左侧面板里选择 Image to Video 模式。接着,我上传了那张通过 GPT Image 2 生成的 DJI Pocket 3 产品参考图。界面里可以看到,HappyHorse1.0 最多支持上传 9 张参考图,不过这次测试我只上传了 1 张。
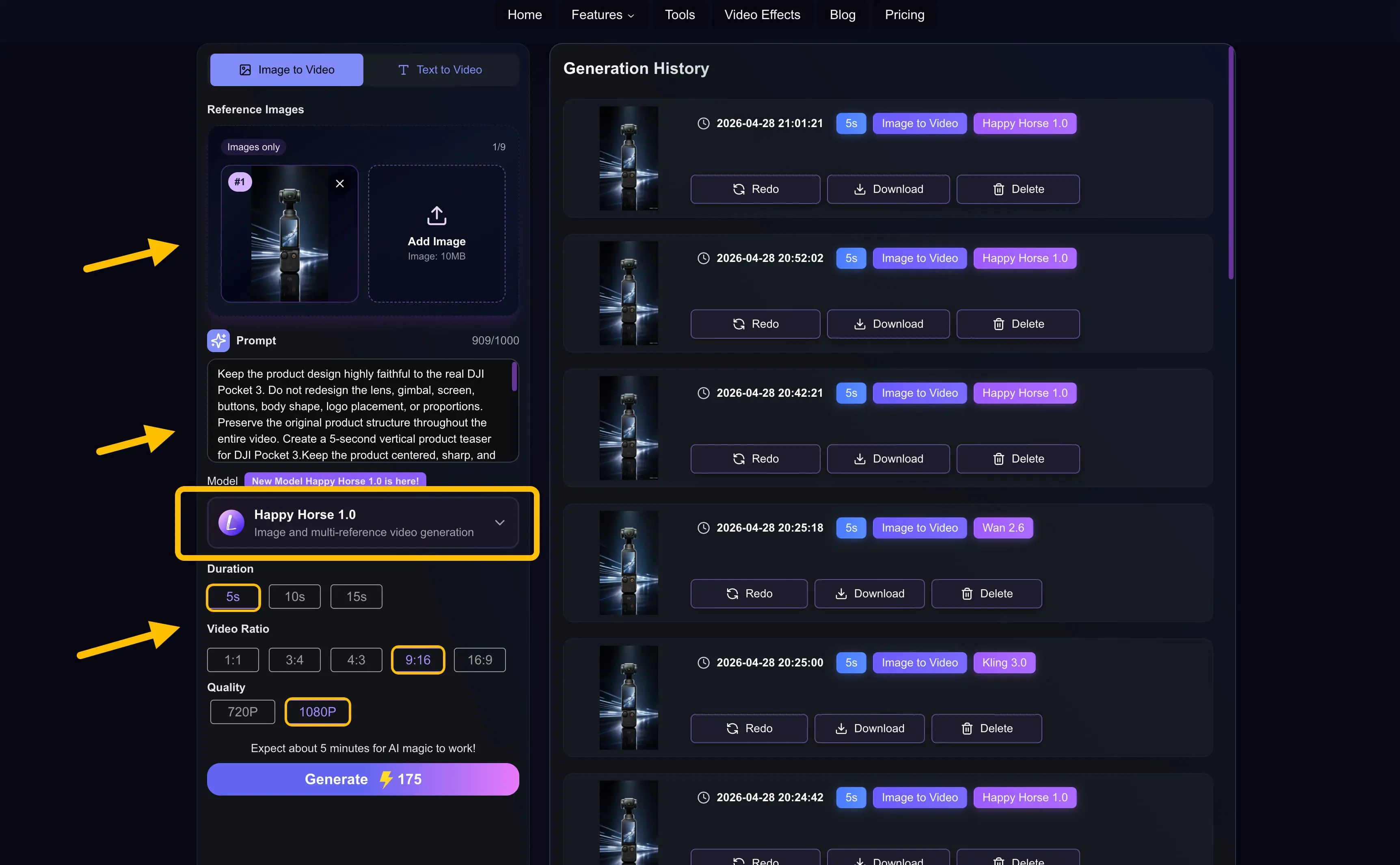
接下来,我在提示词输入框里填入了下面这段提示。需要注意的是,提示词长度必须控制在 1000 字符以内。
让产品设计尽可能忠实于真实的 DJI Pocket 3。不要重新设计镜头、云台、屏幕、按键、机身形状、Logo 位置或整体比例。请在整个视频中都保持产品原有结构。
制作一支 5 秒竖屏 DJI Pocket 3 产品预告片。让产品始终保持居中、清晰,并且结构准确。不要重新设计产品,也不要改变镜头、云台、屏幕、按键或机身比例。
镜头运动:从中等广角产品镜头开始,然后缓慢向镜头部分推进。
灯光:采用戏剧化棚拍光效,使用冷蓝色轮廓光,并让一束柔和的白色高光掠过机身下半部分。
背景:深色、极简、偏未来感的背景,带有微弱蓝色光带和带反射的亮面地面。风格:高端科技广告、电影感产品展示、干净利落的电商广告质感、平滑流畅的运动。这次我选择的参数是:
- 模型: HappyHorse1.0
- 时长: 5 秒
- 视频比例: 9:16
- 画质: 1080P
这次生成大约消耗 175 积分。参数都设置好后,我点击了 Generate 开始生成。实际等待时间大约是 3 到 4 分钟,最后得到了一支这样的 DJI Pocket 3 宣传视频。
从最终结果来看,DJI Pocket 3 始终稳稳地待在画面中心。黑色背景、蓝色光带、冷色高光和反射地面一起把这款数码影像产品应有的科技感拉了出来。
在整个视频里,这台相机的外形和比例都保持得很稳定。镜头、云台和屏幕的位置都没有跑偏,Logo 也比较清晰,没有出现明显的产品畸变或那种很典型的 AI 式“乱改设计”。
与此同时,镜头运动也很顺。明显的推进镜头让观众的注意力自然集中到产品最关键的部位上。
测试 2:多图参考视频生成
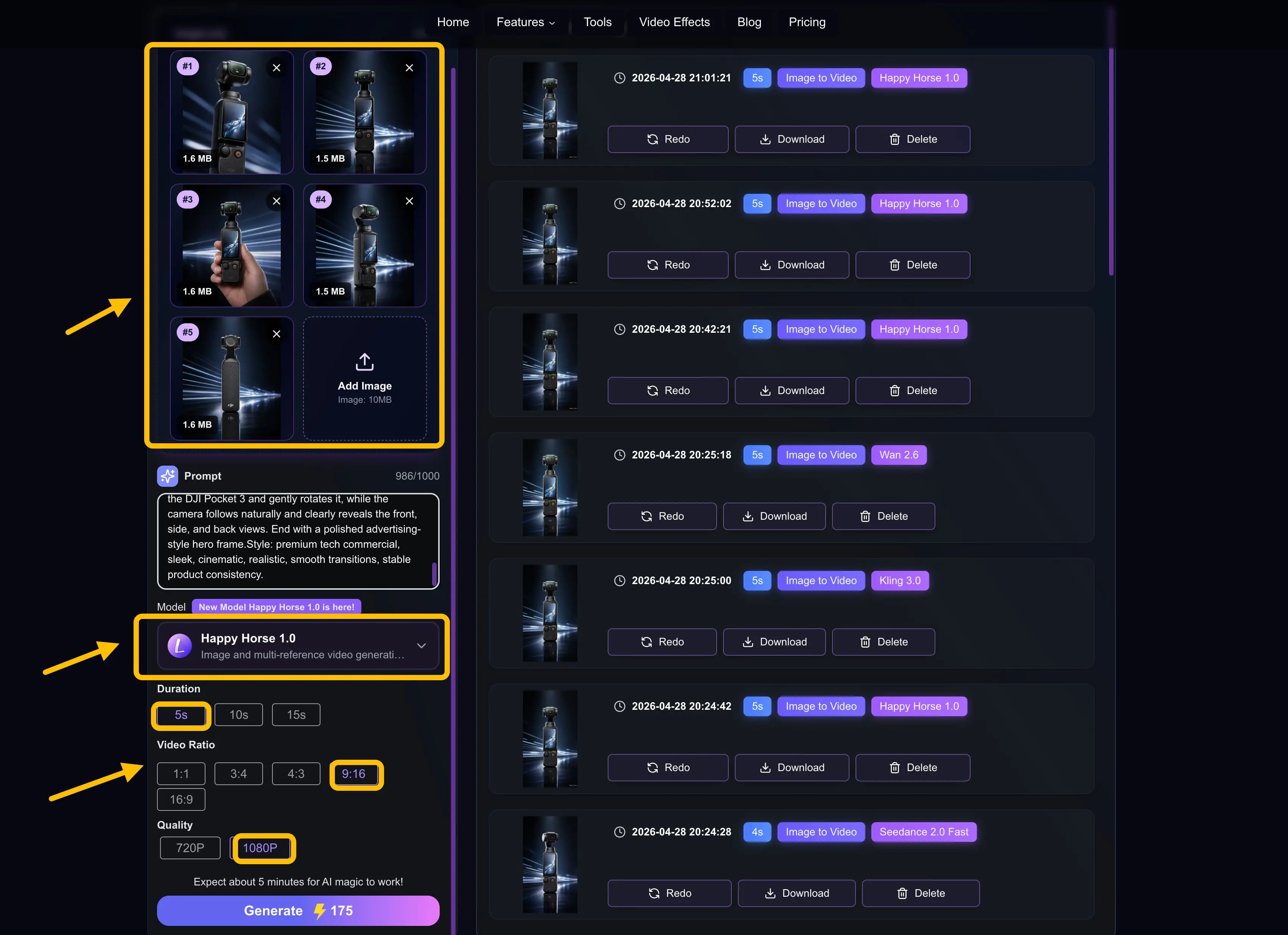
接下来,我想再往前走一步,看看 HappyHorse 1.0 在 多图参考视频生成 这件事上到底表现如何。这一次,我上传了 五张来自不同角度的 DJI Pocket 3 图片,包括正面视角、多个侧前方视角、手持视角以及背面视角。我的目标是看看模型能否从多个视角理解同一件产品,并把这些视角整合进同一支生成视频里。同时,我也想观察在镜头运动过程中,视频能否自然地呈现产品的正面、侧面和背面。
之后我重复了和前面一样的流程:输入提示词、设置参数、开始生成。最终结果如下。
在最终成片里,镜头会从正面慢慢转到侧面,再带出背面,甚至还出现了类似手持视角的 DJI Pocket 3 展示,让整支视频更像一场完整的产品走位展示。你不需要自己手动拍多机位,也不需要后期一条条剪接。
AI 视频生成器会基于这些参考图,自动做出一支带有平滑转场和多角度变化的短视频。对于电商广告、产品预告片以及短视频社媒内容来说,这一点尤其有价值。
测试 3:文本提示词准确性与多镜头运动
最后一个实验里,我只用 text-to-video 来测试 HappyHorse 1.0 在 文本提示词准确性与多镜头运动 方面的表现。我在输入框里写入了以下提示词:
制作一支写实、电影感、多镜头的视频:一位年轻咖啡师在温暖舒适的咖啡馆里制作拿铁。请在所有镜头中保持同一位咖啡师、米色围裙、意式咖啡机、咖啡杯和咖啡馆环境的一致性。核心目标是准确遵循提示词,清晰呈现每个镜头不同的相机运动,并让镜头之间的切换顺滑自然。
镜头 1:用广角建立镜头展示咖啡馆环境,年轻咖啡师站在意式咖啡机前。镜头采用缓慢推进。
镜头 2:中景侧拍,带轻微跟拍,展示咖啡师把手柄锁进咖啡机并开始萃取浓缩。
镜头 3:特写镜头,拍摄浓缩咖啡流入杯中,随后开始倒奶并形成拉花。
镜头 4:俯拍或 hero shot,展示放在木桌上的成品拿铁,拉花清晰可见,并带一点轻微环绕或优雅的俯视移动。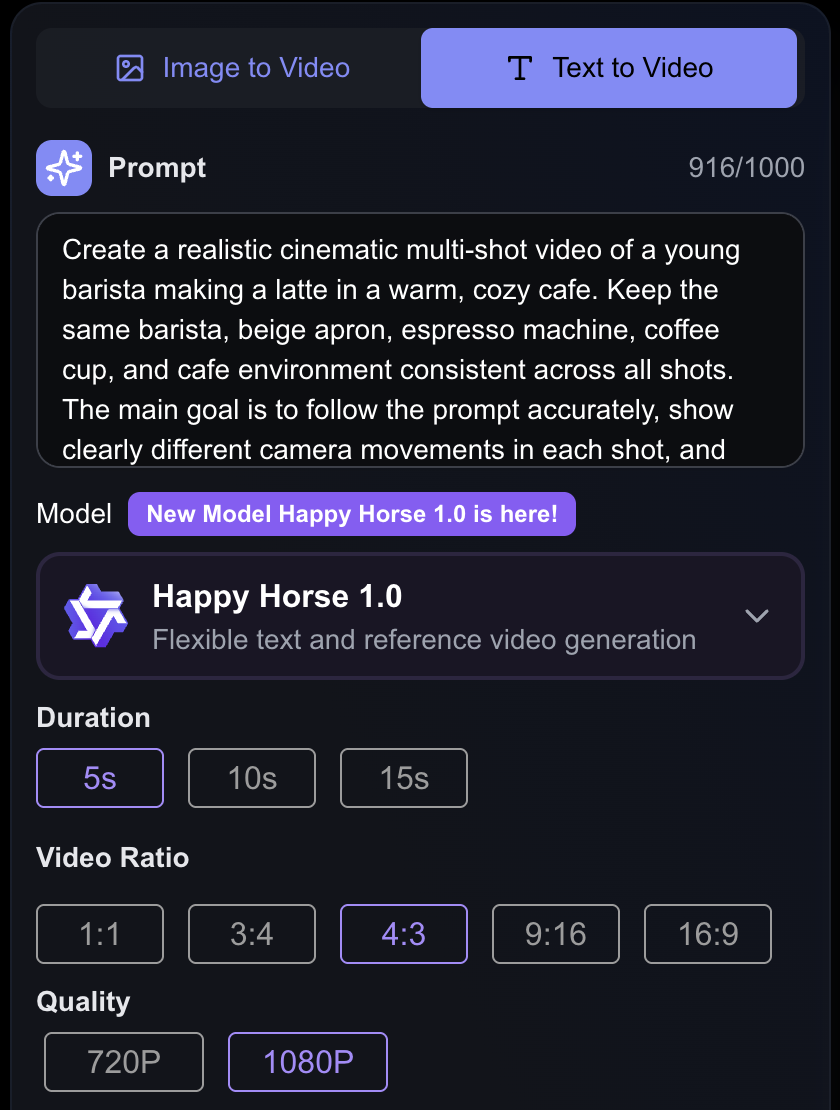
这次我选择的参数是:
- 模型: HappyHorse1.0
- 时长: 5 秒
- 视频比例: 4:3
- 画质: 1080P
和 image-to-video 相比,text-to-video 的生成时间明显更长。我大概等了 5 分钟,最后得到了一支这样的咖啡馆咖啡师做咖啡视频。
这次我没有给 HappyHorse 1.0 任何参考图,所以人物和场景完全由模型自己想象生成。不过从提示词准确性来看,结果依然相当不错。温暖的咖啡馆氛围、年轻咖啡师、围裙、咖啡机、杯子以及整个做拿铁的过程都出现了,整体没有明显跑题。
我最满意的一点,是 HappyHorse 1.0 对提示词里镜头结构的理解。在最终视频里,你能比较清楚地看到不同镜头带来的层次感:广角建立镜头、中景侧拍、特写镜头,以及俯拍或 hero shot。它在短短 5 秒里完成了多镜头切换。
在我看来,这次测试体现了 HappyHorse 1.0 最有价值的一项能力:它可以理解相对复杂的镜头规划,做出更平滑的镜头切换,并尽量把这些镜头组织成一支连贯的视频。
HappyHorse 1.0 仍然会出问题的地方
不过,测试完以后,我也不会说 HappyHorse 1.0 已经能做到“每次都直接生成可发布成片”。它的画面表现和镜头规划能力确实很亮眼,但只要视频里涉及真实产品、近景人物,或者更长时间的连续运动,你还是需要认真复查结果。
例如在产品视频里,模型有时仍然会擅自改动一些小细节,因此结果不一定与真实产品完全一致。人物视频也是一样。短片通常更稳定,但一旦动作更复杂或镜头更长,面部、手部、服装等细节还是可能出现小幅漂移。
HappyHorse 1.0 最适合哪些人?
短视频创作者
如果你在做 TikTok、Reels、Shorts 或社交广告,HappyHorse 1.0 很值得一试。
短视频最需要的是快速抓人眼球、强视觉、竖屏格式和高频变体,这正是 HappyHorse 1.0 相对擅长的地方。
它并不适合从头到尾讲完整故事,更适合生成一个足够有力的视觉瞬间:比如产品特写、电影感运动镜头、预告片镜头,或者一段能让人停下滑动的视频素材。
电商品牌团队
HappyHorse 1.0 也很适合电商团队。
大多数品牌并不缺产品照片,真正缺的是足够多的视频内容,用于广告、落地页、商品详情页和社交媒体。
只要参考图选得对,一张产品图就能变成竖屏预告片、棚拍风展示、生活方式草稿,或者商品页上的轻量动态素材。
当你需要大量创意变体,又不想每个创意都重新拍摄时,它就非常有用。
广告创意人员
对广告创作者来说,它最大的价值是速度。
在真正制作完整 campaign 之前,你往往需要先测试 hook、场景、产品、风格和格式。
HappyHorse 1.0 很适合这个前期阶段。它能让你在投入更多剪辑、制作和打磨成本之前,先快速判断一个视觉方向是否值得继续。
概念设计师与分镜创作者
HappyHorse 1.0 也能帮助做视觉预演。
如果你手上有静态画面、产品概念图或分镜图,它可以把静帧快速转成动态预览。
这对于提案、活动规划或验证一个创意在运动中是否成立都很有帮助。它不能取代完整制作流程,但能让前期概念阶段更快、更直观。
最终结论
做完这三轮测试后,我会认为 HappyHorse 1.0 确实是一个有潜力减少常见 AI 视频生成失败的选项。
它当然不是一个按下去就保证每次都完美出片的“魔法按钮”,但对于重视产品准确性、提示词控制力和镜头切换流畅度的创作者来说,它的潜力已经很明显了。
如果你也想复现这套流程,可以直接在浏览器里使用 Lanta AI 的 AI Video Generator,亲自测试 HappyHorse 1.0 在 image-to-video、多图参考生成和 text-to-video 上的表现。
你也可以直接进入 HappyHorse 1.0 模型页面,把它和 Lanta AI 里其他视频模型的定位做一个更直观的比较。